Ask Your Documents
Upload source files, ask natural-language questions, and stream cited answers with full control over spend, access, and hygiene.
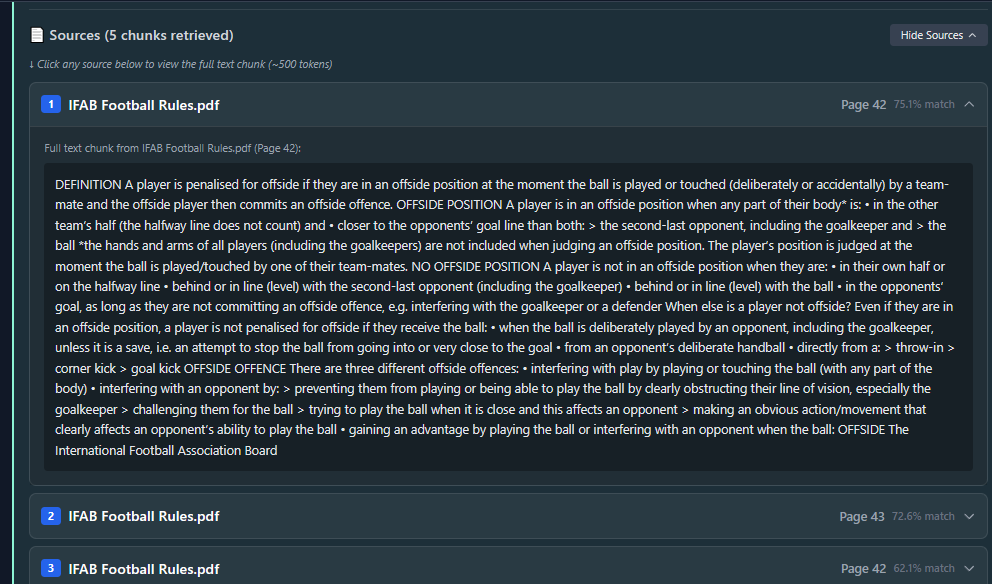
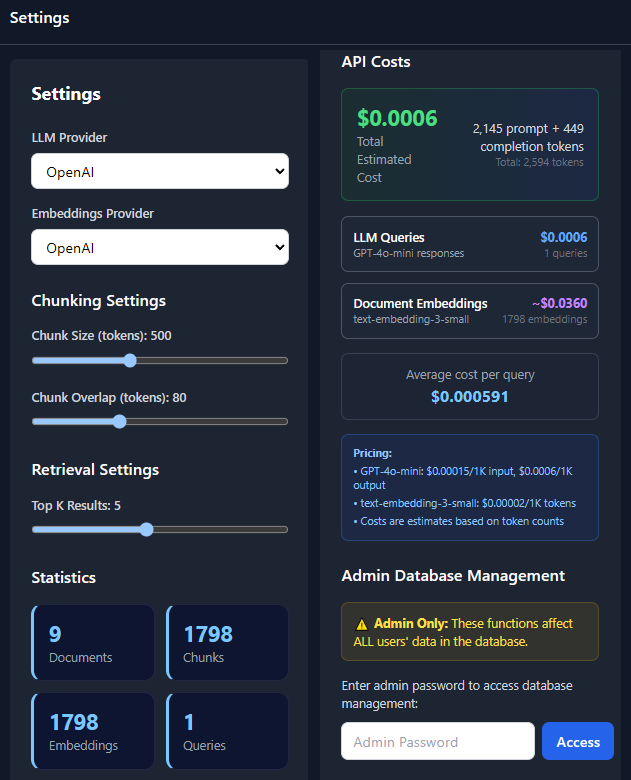
How it works in 60 seconds
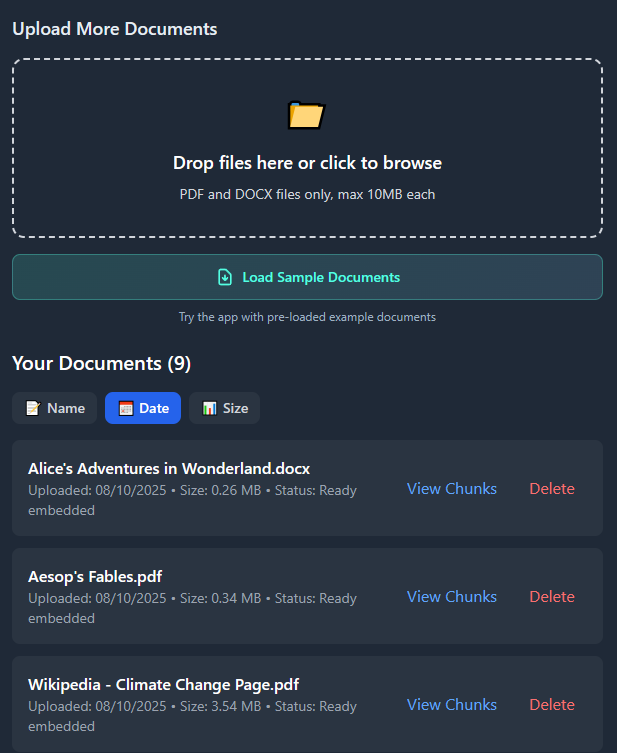
- Drag-and-drop ingestion cleans, chunks, and tags PDFs or DOCX files with automatic deduplication.
- Hybrid retrieval combines semantic search and keyword boosts while logging cost, latency, and hit confidence.
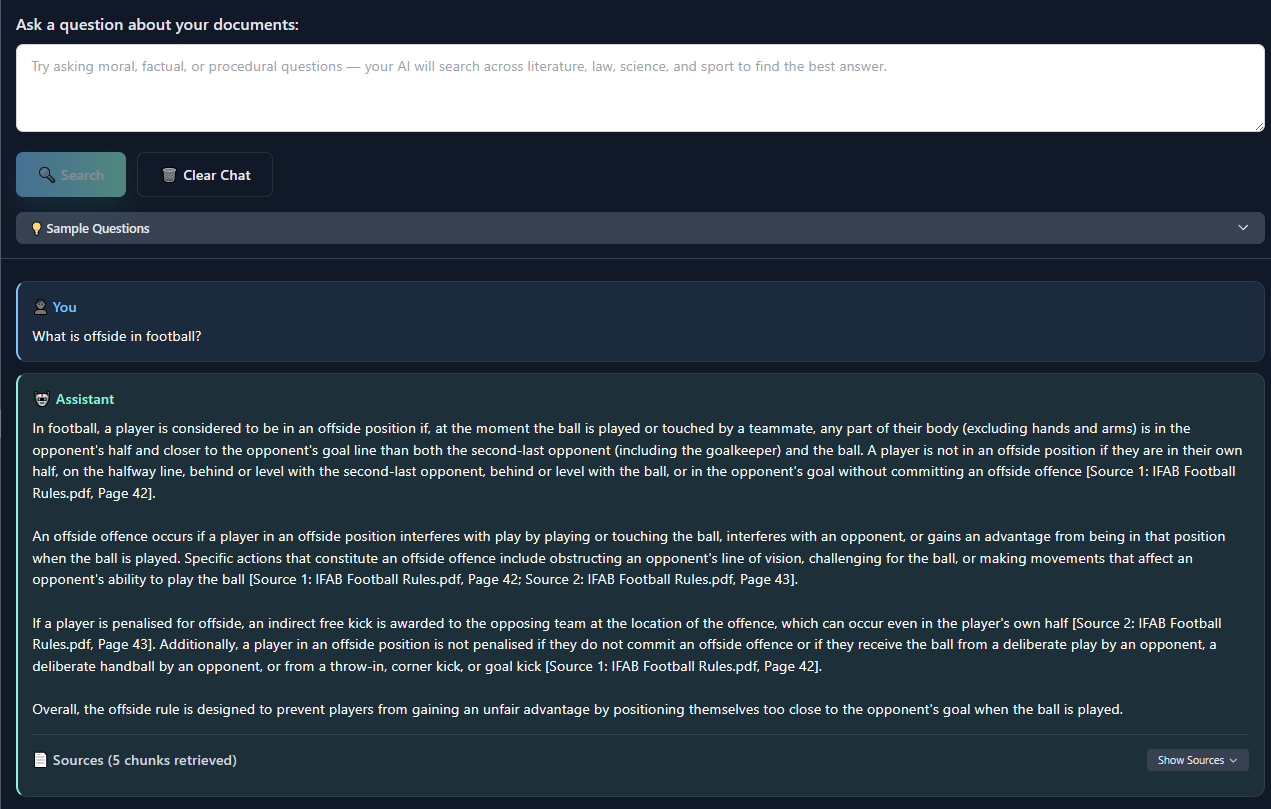
- The chat workspace streams answers with inline citations, snippet previews, and admin-grade audit trails.
How it works
Three simple beats keep the flow explainable while orchestration runs async.
1. Prepare
FastAPI orchestrates file intake, text extraction, chunking, and metadata tagging while Postgres/pgvector store embeddings.
2. Retrieve
A hybrid query fuses semantic and keyword signals, filters by permissions, and sends the context bundle with cost controls.
3. Respond
Server-Sent Events stream the answer through Next.js, citing each chunk, logging usage, and teeing up follow-up prompts automatically.
Why it matters
Each audience gets clear, fast wins without parsing the entire architecture doc.
Product & Engineering
- RAG pipeline with hybrid search, cost controls, and operational safeguards.
- Vector database management with proper indexing and query optimization.
Marketing & Enablement
- Instant cited answers with document references and confidence scores.
- Admin controls for data hygiene, quotas, and user management.
Storytelling & Recruiting
- Shows end-to-end ownership from document ingestion to cited answers.
- Highlights RAG architecture, vector search, and operational excellence.
Want to dig deeper?
Kick the tires here or jump straight into the architecture notes.
Architecture deep dive
Diagrams, delivery notes, and roadmap in one expandable overview.
Inside the workflow
- RAG pipeline stages: ingest, parse, chunk, embed, store, retrieve, cite, and answer.
- Message broker keeps uploads responsive while heavy work runs asynchronously.
- Streaming chat keeps context tight by truncating history using token-aware heuristics.
Experience specifics
- Upload modal includes validation, sample docs, and inline chunk previews.
- Answer panel highlights citations, cost, and latency with subtle animations.
- Admin view exposes storage usage, embedding counts, and data reset tools.
Stack & tooling
Backend
- FastAPI with async workers orchestrating extraction, embeddings, and vector search.
- Postgres + pgvector manage metadata, embeddings, and audit logs.
Frontend
- Next.js 14 with server actions for secure ingest and SSE handling.
- Tailwind design tokens echo the Arctic Wallaby brand system.
DevOps
- Docker Compose parity for API, UI, Postgres, and worker services.
- Nginx handles routing, TLS termination, and static asset delivery.
Architecture map
Delivery notes & roadmap
- Automation scripts reset the database, seed sample docs, and verify provider connectivity before demos.
- Next steps: query analytics dashboard, CLI ingest tooling, and multi-tenant tenancy exploration.
Want to ship something similar?
I handle RAG systems, vector databases, and document processing pipelines. Let's talk about your data grounding roadmap.