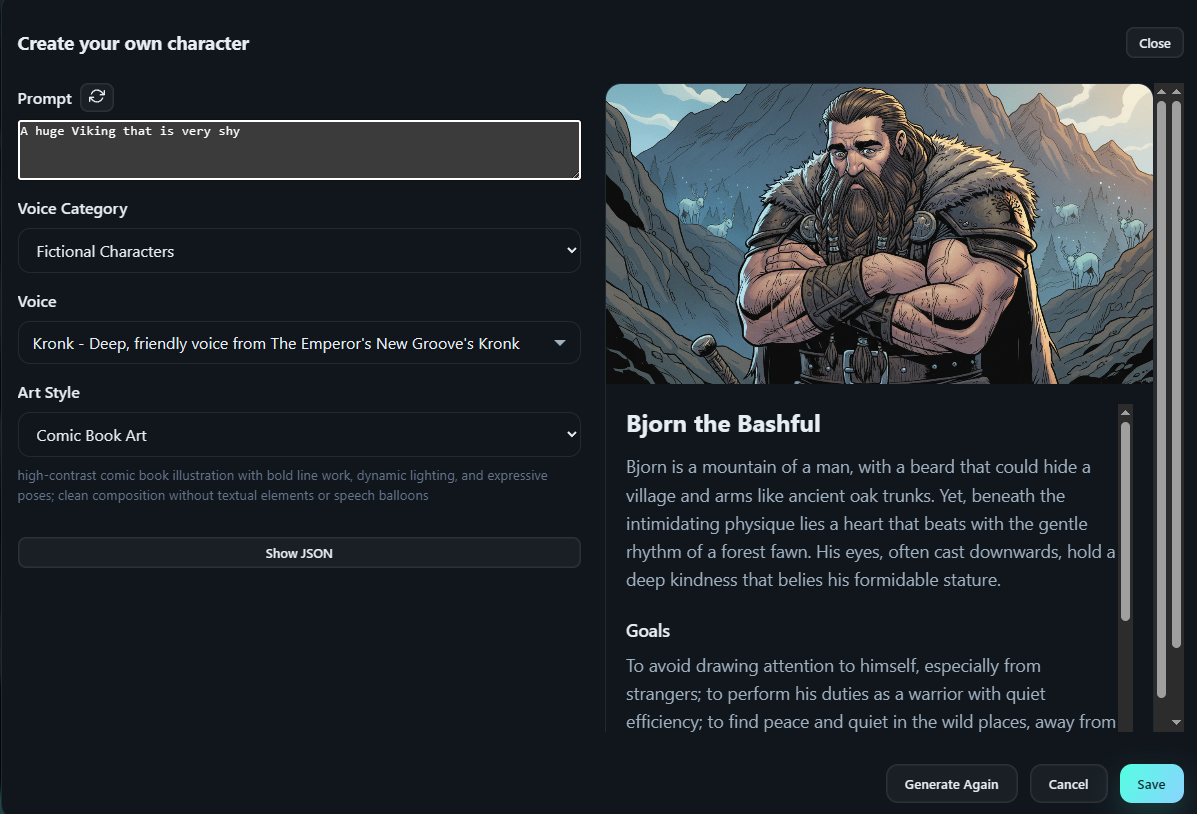
Play The Part
A live voice agent with semantic retrieval (RAG), customizable voices, and AI-generated images that match conversations. Perfect for roleplay, NPCs, and interactive AI experiences.
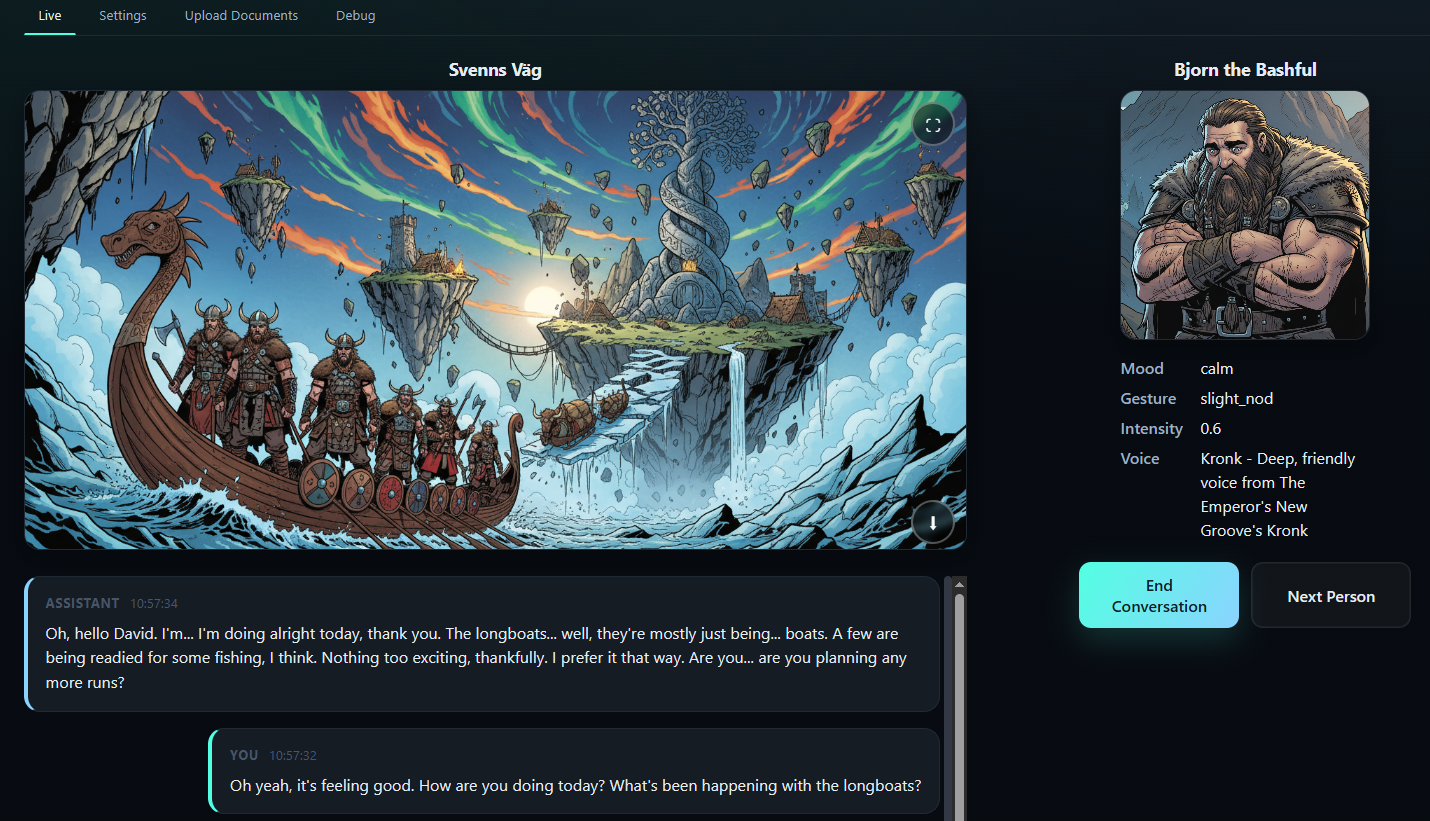
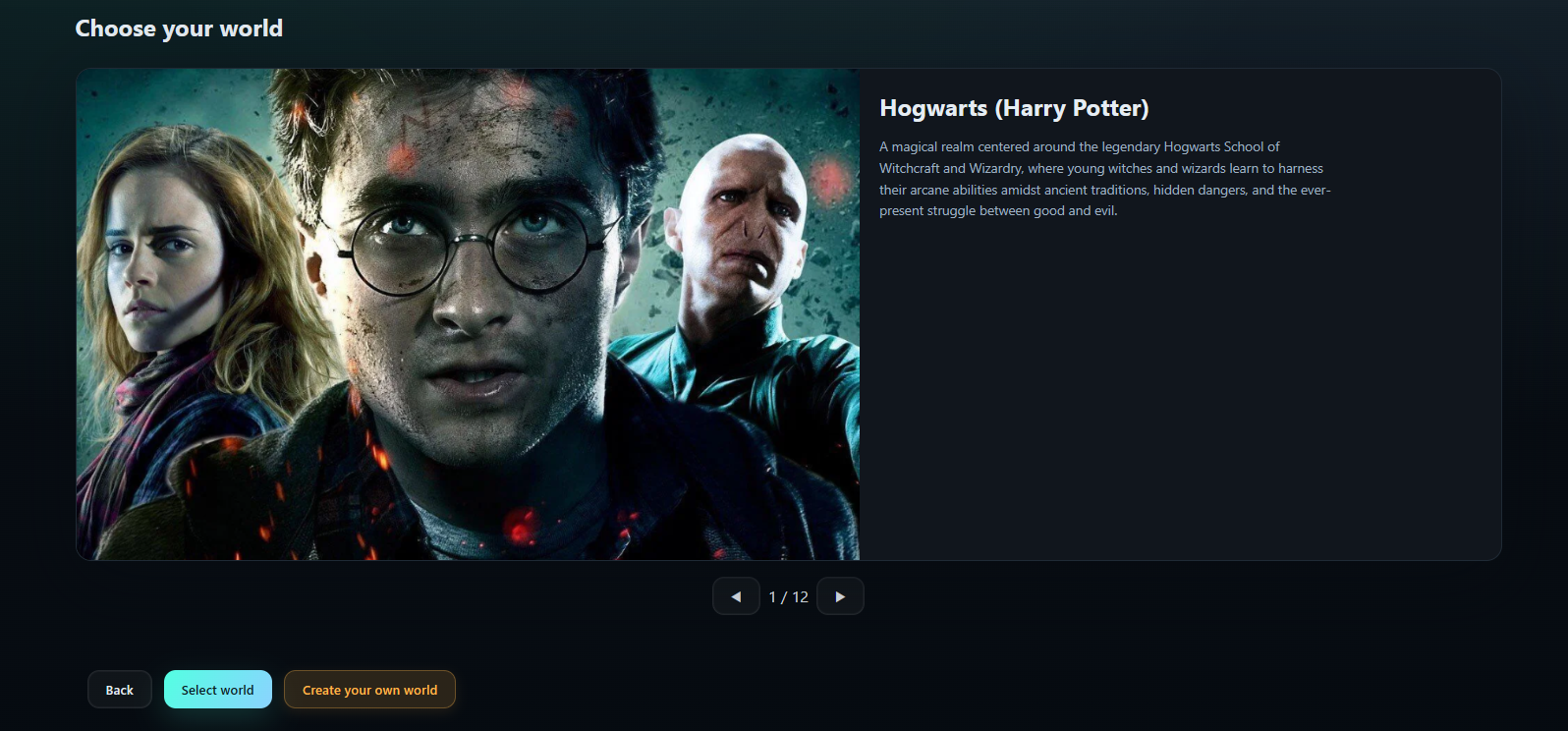
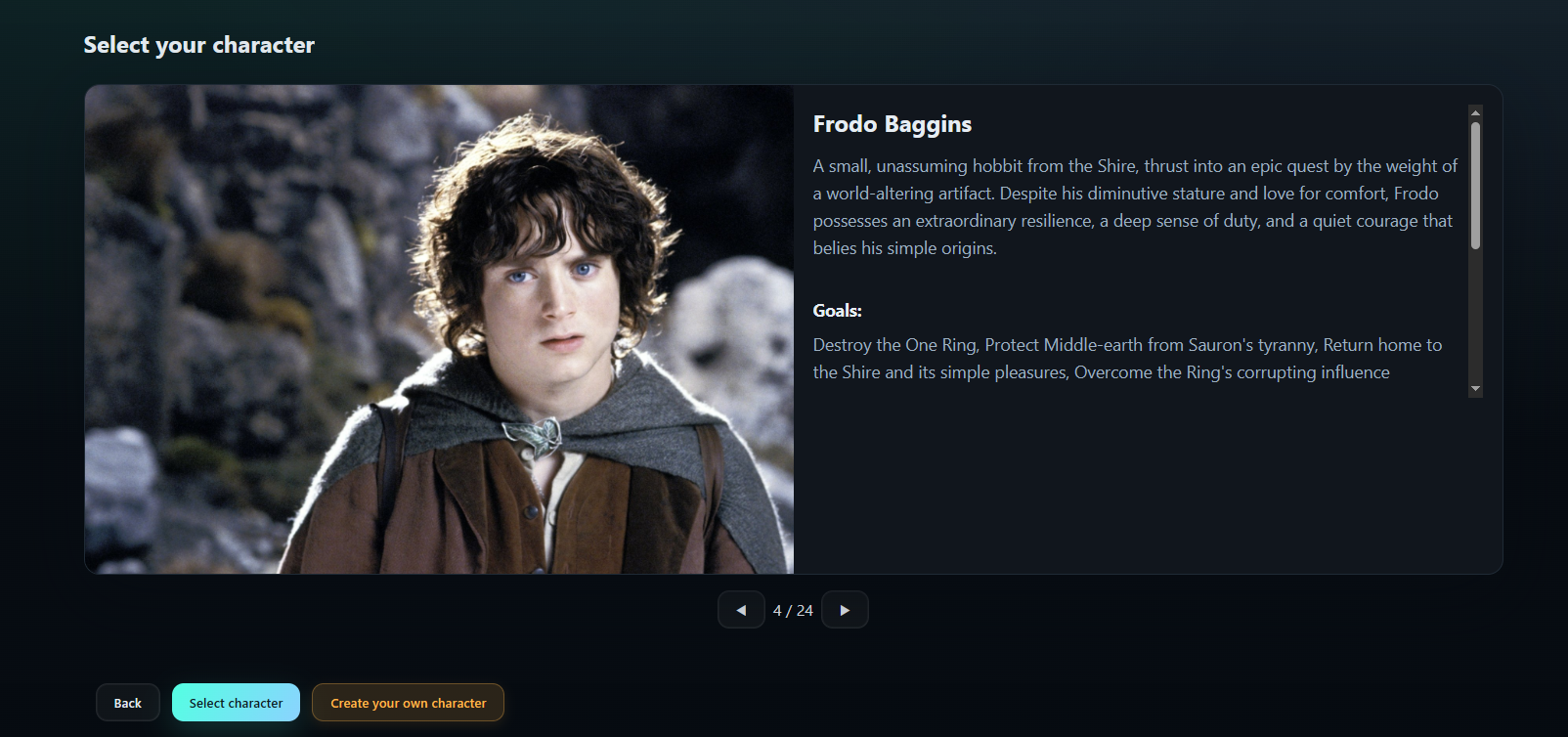
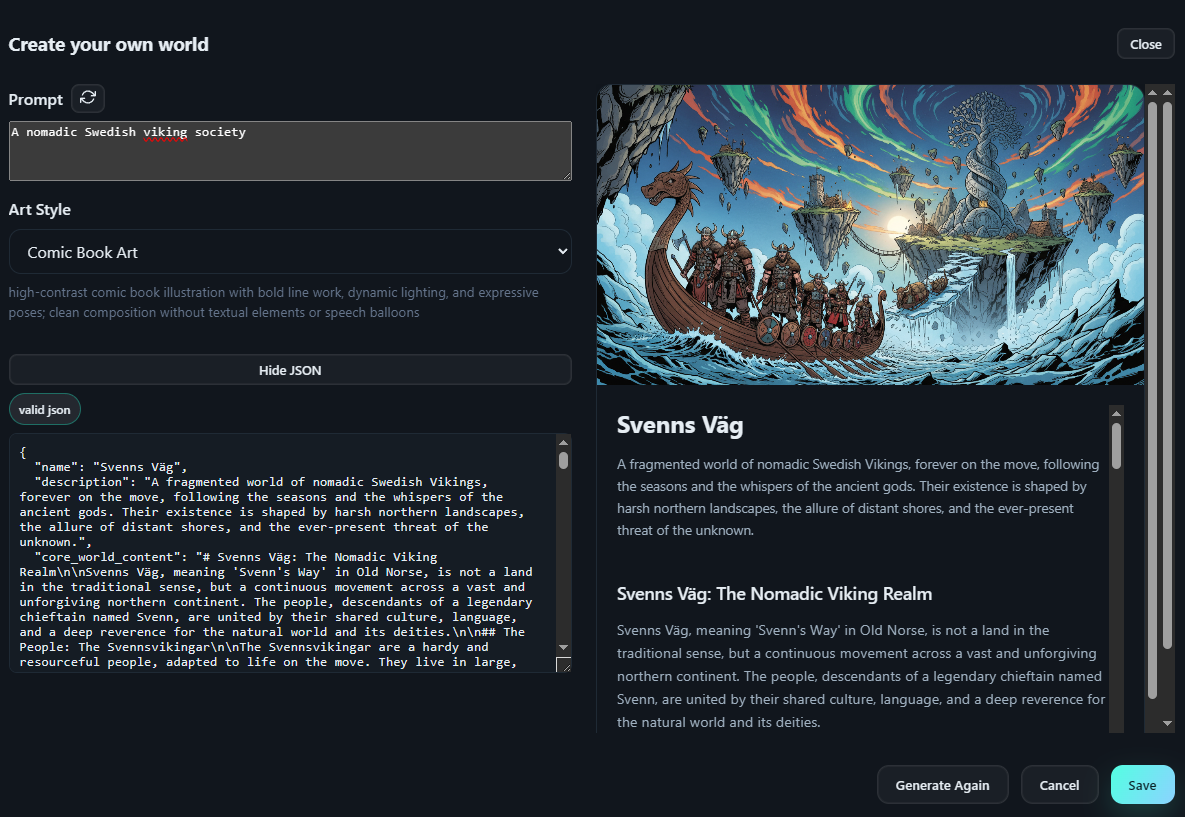
How it works in 60 seconds
- Voice agent setup: choose personality, select from hundreds of customizable voices (Piper TTS), and conversation context before the first exchange.
- Client streams push-to-talk audio while the backend transcribes speech and triggers semantic RAG to retrieve relevant context.
- Custom knowledge bases are persisted via FastAPI endpoints, embedded with Gemini vectors, and retrieved in under two seconds.
- Gemini drafts responses, Piper voices them with customizable pitch/speed, AI generates matching images, and telemetry streams back to the UI.
How it works
Three orchestrated loops keep conversations fluid with semantic retrieval, customizable voices, and AI-generated images.
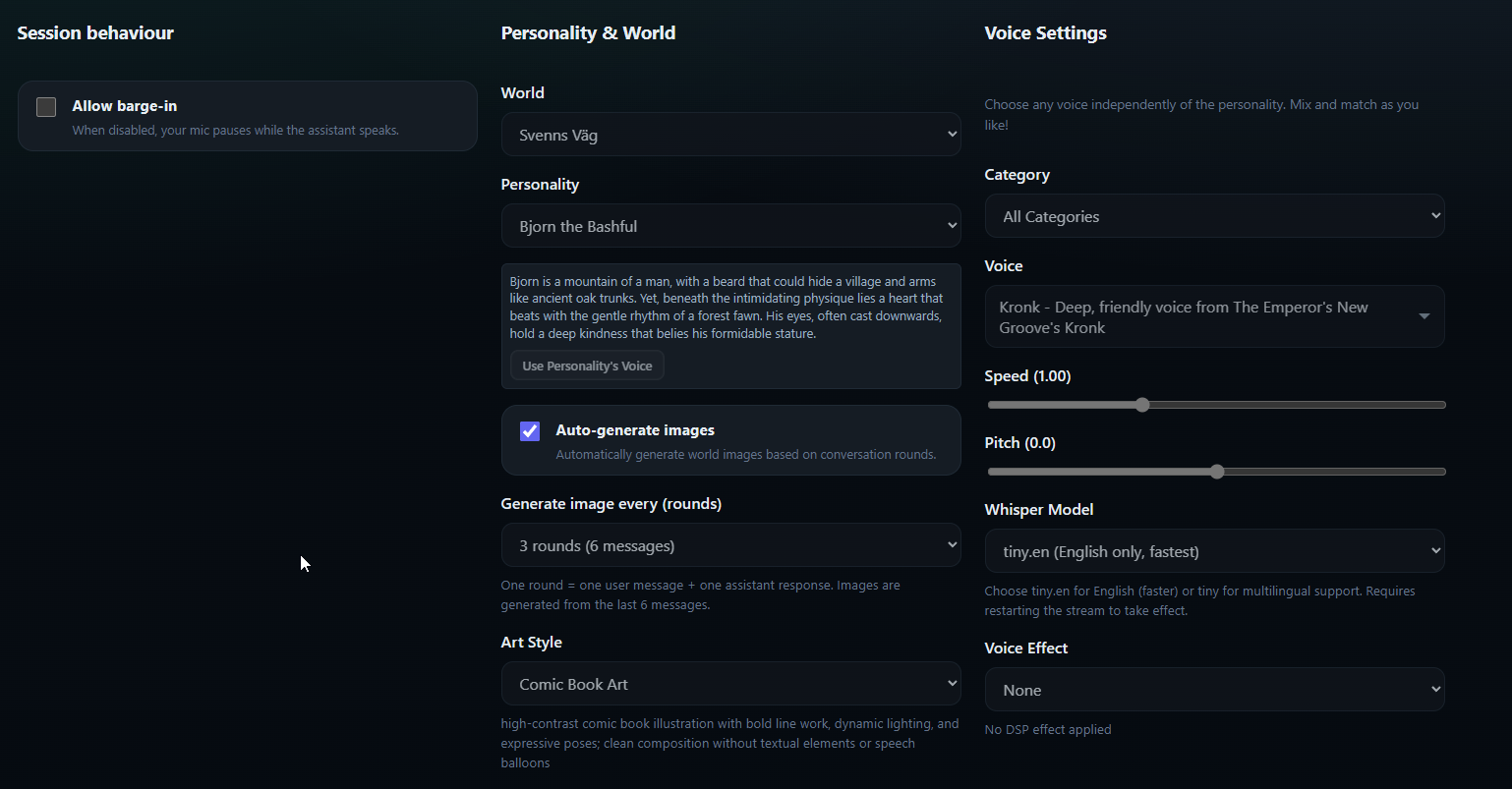
1. Configure the agent
Wizard fetches knowledge bases, personalities, and hundreds of customizable Piper voices, applies saved settings, and primes voice config for the session. New knowledge bases flow through REST endpoints, land in Postgres with pgvector, and trigger embedding jobs for semantic retrieval.
2. Process the input
Push-to-talk audio streams over WebSocket, with client VAD marking utterance edges and faster-whisper returning live transcripts. Each utterance kicks off a semantic RAG lookup that retrieves ranked context from knowledge bases in under two seconds.
3. Deliver the response
Gemini composes dialog with retrieved context, the pipeline generates matching images via AI, Piper renders speech with customizable pitch/speed, and telemetry streams back to the UI. Perfect for voice agents, roleplay NPCs, and interactive experiences.
Why it matters
Each team gets fast insight into how voice agents with RAG stay accurate, consistent, and engaging.
Product & Engineering
- Session state machine centralizes barge-in, resume, and error handling across web clients.
- Semantic RAG returns relevant context in ~2 seconds, keeping responses grounded in knowledge bases.
- Customizable voice parameters (pitch, speed, speaker selection) enable brand-appropriate TTS across use cases.
- AI-generated images match conversation context, adding visual richness to voice interactions.
Voice Agents & RAG
- Knowledge base slots make it trivial to add domain-specific content without rewriting prompts.
- Memory service blends semantic retrieval with per-session context for accurate, consistent responses.
- Great for customer support agents, educational NPCs, interactive storytelling, and roleplay experiences.
Robotics & Ops
- Mood/gesture payloads publish over MQTT, ready to animate LED faces or servo rigs.
- Pipeline metrics log ASR, LLM, RAG, and TTS timings to keep the 1-2 second latency budget honest.
Want to dig deeper?
Try the live demo or explore the architecture docs first.
Try the voice agent
Experience semantic RAG, customizable voices, and AI-generated images in a live conversation.
Launch demoArchitecture deep dive
Under the hood walkthrough: semantic RAG, voice synthesis, and AI image generation in one orchestrated loop.
Inside the voice agent pipeline
- Pipeline runs an async state machine: capture, transcribe, semantic RAG, call Gemini, generate images, synthesize speech, stream audio.
- Partial flush logic emits text chunks as soon as Gemini replies cross thresholds, keeping captions ahead of audio.
- Voice activity detector plus barge-in policy lets users interrupt the agent without losing session context.
- Every response starts with a semantic RAG lookup that embeds the fresh user utterance and returns relevant knowledge base context in ~2 seconds.
- AI image generation creates contextual visuals based on conversation topics, enhancing the multimodal experience.
Experience specifics
- React app drives a four-step wizard, live session view, settings tab, and debug telemetry dashboard.
- Voice selector surfaces hundreds of customizable Piper models with pitch/speed controls, speaker selection, and built-in personas for roleplay scenarios.
- Debug view streams prompt JSON, RAG retrieval results, latency metrics, and raw Gemini outputs for tuning.
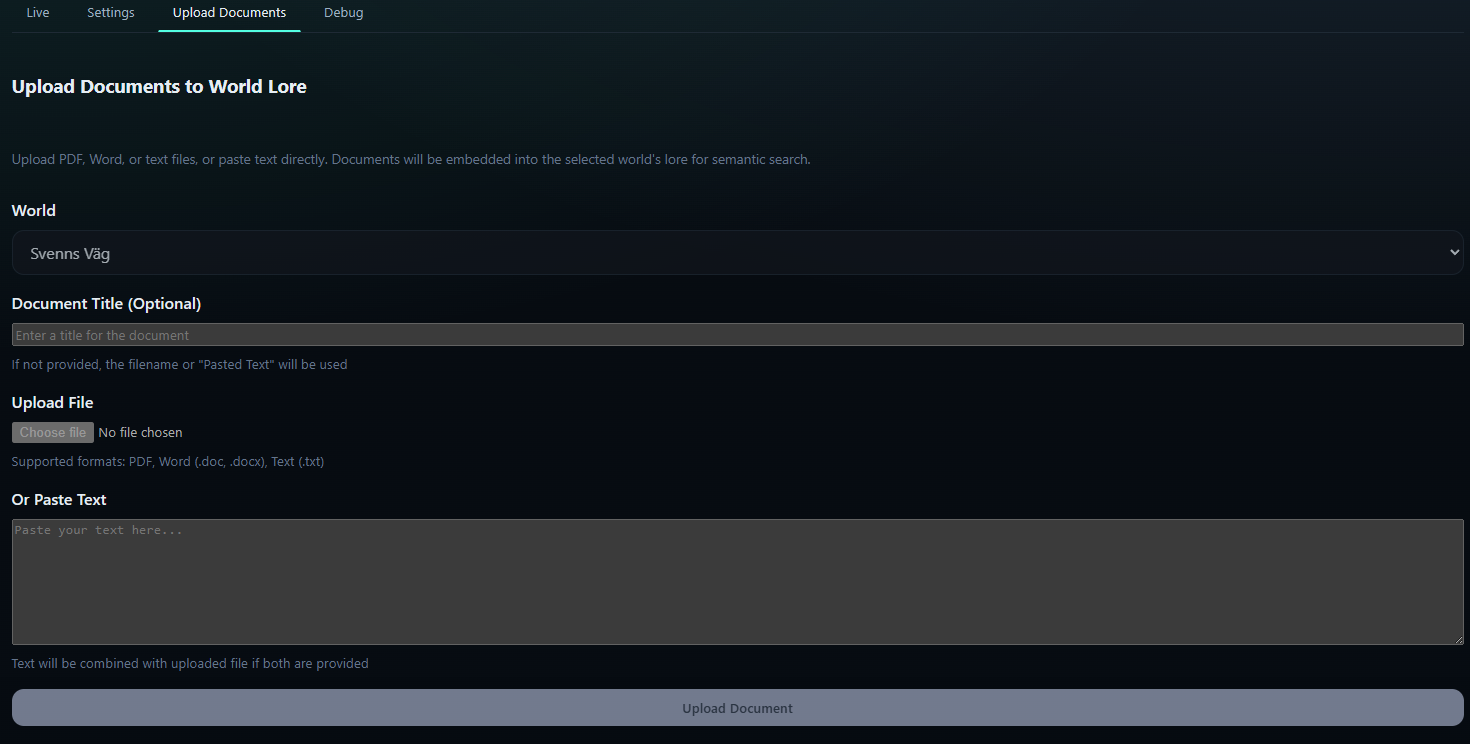
- Create knowledge base and character modals upload content, imagery, and voice configs so new data is searchable immediately after embedding finishes.
- AI image generation displays contextual visuals that match conversation topics, updated dynamically during the session.
Stack & tooling
Backend
- FastAPI orchestrator ties Speech-to-Text, semantic RAG, Gemini, image generation, Piper TTS, and robot filter DSP in asynchronous tasks.
- RAG service combines semantic retrieval from knowledge bases with recent dialog context before LLM calls.
- Create knowledge base/character flows persist records, compute embeddings with pgvector, and surface them immediately to the next Gemini prompt.
Frontend
- React + TypeScript client handles audio record/playback, WebSocket messaging, image display, and UI state machines.
- Settings tab persists voice customization (pitch/speed), speaker selection, and art style prompts for AI-generated imagery.
DevOps
- Docker Compose bundles FastAPI, Postgres, Piper, and optional MQTT broker for robot events.
- Observability hooks emit structured logs and latency counters to Grafana-ready exports.
Architecture map
Delivery notes & roadmap
- Pipeline exposes per-stage timers, token usage, RAG retrieval accuracy, and ASR accuracy metrics for regression tracking.
- Next phase: multi-agent conversations, local wake-word tuning, CDN-backed asset delivery, and enhanced image generation context matching.
Want to ship something similar?
I build voice agents with semantic RAG, customizable voices, AI-generated images, and compliant consent flows. Perfect for customer support, education, roleplay, and interactive AI. Let's talk about your roadmap.